Design Paradigm
One of the most important aspects of the design of SkyhookDM is that it allows building in-storage data processing systems with minimal implementation effort. The design allows extending the client and storage layers with widely-used data access libraries requiring minimal modifications. We achieve this by (1) creating a file system shim in the object storage layer so that access libraries embedded in the storage layer can continue to operate on files, (2) mapping client requests-to- be-offloaded directly to objects using file system striping metadata, and (3) mapping files to logically self-contained fragments by using standard file system striping.
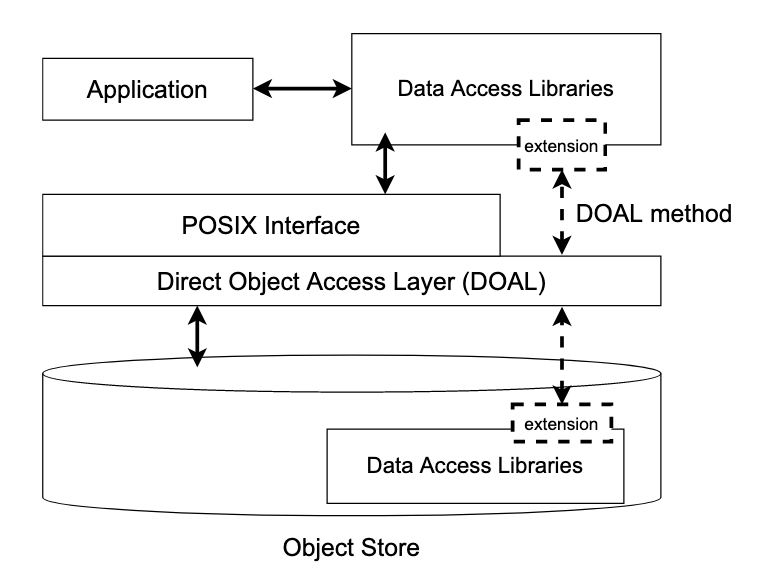
Architecture
SkyhookDM is the approach that allows extending both the client and storage layers of “programmable object storage systems” with plugins to be able to provide data management and processing tasks directly within the storage layer. The goal of SkyhookDM is to allow users to transparently grow and shrink their data storage and processing needs as demands change, offloading computation and other data management tasks to the storage layer in order to reduce client-side resources needed for data processing in terms of CPU, memory, I/O, and network traffic. Our implementation of SkyhookDM is currently within Ceph, but is not Ceph specific, rather the approach is applicable to any object storage system with extensibility features such as user-defined object classes. The overall architecture of SkyhookDM is shown below.
Storage Layer: SkyhookDM is built by extending both the filesystem and object storage layers in the Ceph storage system. Ceph allows extending its object storage interface, RADOS, with C++ plugins (built using the Ceph Object Class SDK) which inturn allows embedding application specific methods inside the Ceph OSDs for direct access and manipulation of objects within the storage layer. We leverage this feature of Ceph and extend RADOS by implementing Object Class methods that utilize Arrow APIs to scan objects containing Parquet binary data inside the storage layer. Since the Arrow APIs expect a file-like object to work on, we implement a random access interface between the Arrow access and RADOS layers. This random access interface is analogous to the
ObjectInputFileinterface in the Arrow S3FS module and provides a similar file-like view over RADOS objects.Client Layer: Apache Arrow provides a
DatasetAPI which provides a dataset abstraction over a collection of files in different storage backend like S3 and HDFS and allows scanning them. TheDatasetAPI supports scanning files of different formats via itsFileFormatabstraction. We extend theParquetFileFormatAPI to create aSkyhookFileFormatAPI which when plugged into theDatasetAPI enables offloading Parquet dataset scans to the storage layer. In SkyhookDM, we store datasets in the Ceph filesystem, CephFS, to utilize the filesystem metadata support it provides via Ceph Metadata Servers (Ceph MDS) for doing dataset discovery. While scanning, we leverage the filesystem metadata, especially the striping strategy information, to translate filenames in CephFS to object IDs in RADOS and call Object Class methods on these objects, essentially bypassing the filesystem layer.
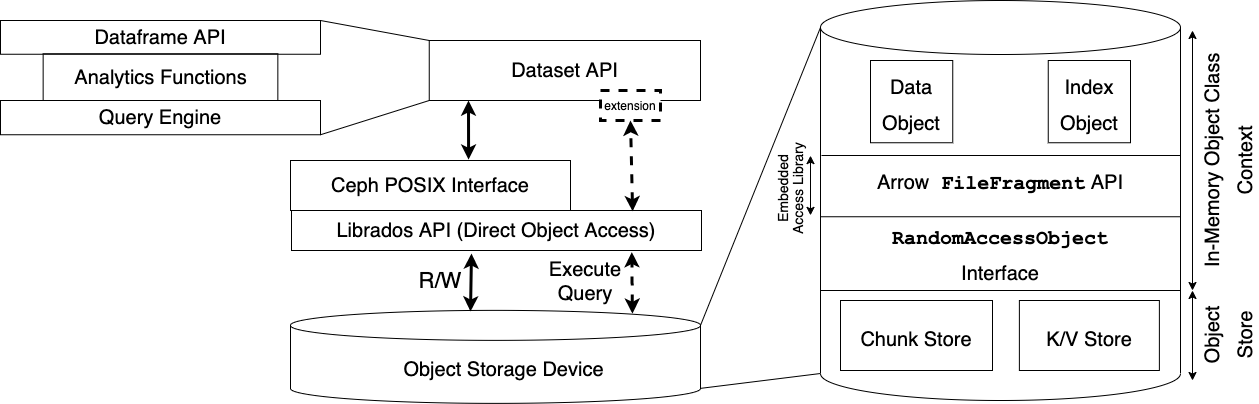
Lifetime of a Dataset Scan in SkyhookDM
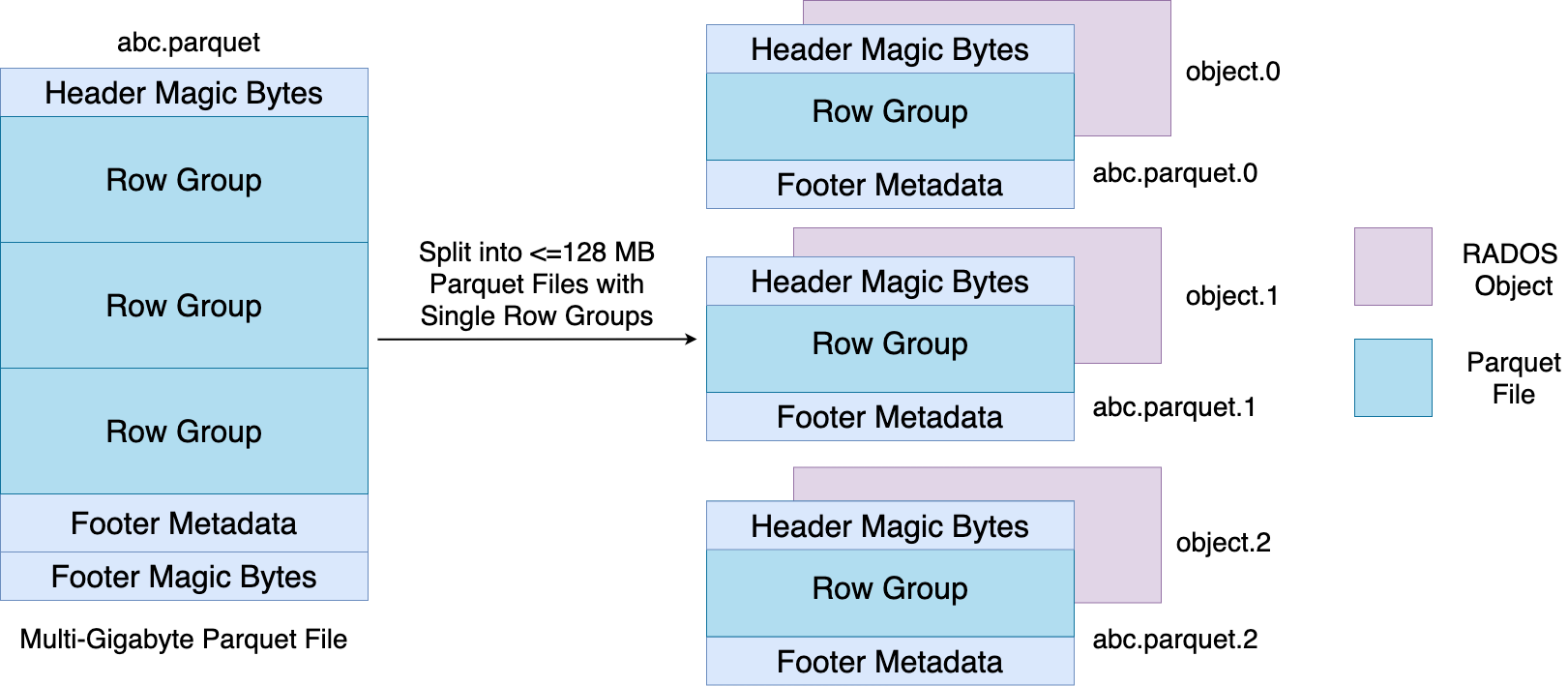
Write Path: Datasets containing Parquet files or a directory heirarchy of Parquet files are written to a CephFS mount. While writing, each Parquet file is splitted into several smaller Parquet files of size
<= 128 MBby theSplittedParquetWriter. We configure the stripe unit in CephFS to be 128 MB to ensure a1:1 mappingbetween a file and an object. The file layout is shown in the figure below. The reason behing choosing 128 MB as the stripe size is because Ceph doesn’t perform well with objects any larger than 128 MB. Also, some of our performance experiments have shown most optimal performance with 128 MB Parquet files. Once the Parquet files are written to CephFS, they are ready to be scanned via theSkyhookFileFormat.
Read Path: At the time of scanning, when the
Executemethod is called on aScanTask, first the size of the target file is read via astatsystem call and theScanOptionscontaining the scanExpressionandProjection Schemais serialized into aceph::bufferlistalong with the file size for sending it to the storage layer. Next, theSkyhookDirectObjectAccessinterface is invoked with the serializedScanOptionsto scan the file within the Ceph OSDs bypassing the filesystem layer. Inside theSkyhookDirectObjectAccesslayer, the file inode value is converted to the corresponding object ID in RADOS and then using thelibradoslibrary, a CLS method call is invoked over the object. Inside the CLS method, first theScanOptionsis deserialized back into theExpressionandSchemaobjects. Then theRandomAccessObjectinterface is intialized over the object to get a file-like instance which is plugged into theParquetFileFragmentAPI for scanning the object. The resultant ArrowTableis written into an LZ4 compressed Arrow IPC buffer and is sent back to the client. Finally, on the client, the buffer is decompressed and the resultingRecordBatchesare returned.